@see
以下引用
gunosy_score_20181116_0
gunosy_score_20181116_1
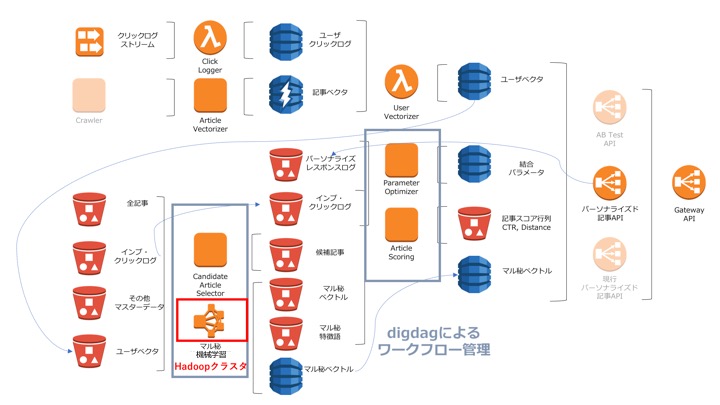
>ざっくりまとめると
- 後述の計算モデルに必要なものは全てDynamoDBとs3におく
- 関連するほぼすべてのタスクのワークフローはdigdagにより管理
- 例外はリアルタイム性を求められるユーザーベクトルを生成するAWS lambda
こんな感じです。digadagの運用とリアルタイムベクトル生成AWS lambdaについては後日別記事で解説します。
開発言語ですが
- Spark on EMRクラスタを用いてマル秘機械学習を行っている部分はScala
- パーソナライズド記事リスト返す記事APIはgolang
- その他タスクは基本的にpython
と言った感じです。
クライアントからのリクエストは必ず一番右にある Gateway API を介し、ABテストのために複数存在する記事APIのうち、どのエンドポイントを叩くかを制御しています。これにより無駄なifを書くことなく、つまりソースコードを汚すことなくABテストを行うことが可能となっています。幸せですね。
以降の§では、記事APIがどのような計算モデルによって記事をスコアリングし、リストを生成するかについて述べていきます。
もくじ
§4. スコア計算モデルとハイパーパラメータ
まず最初に、スコア, スコア計算モデルという言葉の定義をはっきりさせておきます。
スコアとは記事を出すべきかを表す数値のことです。候補となる記事全てに対してスコアを計算し、それを元にソートしてからユーザーに表示するというのが基本的なアルゴリズムになります。
スコア計算モデルとは、ユーザー u
と 記事 a
を引数にしてスコアを算出する時間によって変化する関数 st
st:{ユーザー}×{ニュース記事}→R, (u,a)↦st(u,a), t:時間
のことです。我々の目標はより”良い” st
を構築する事ですが、その制約条件として
リアルタイムに数千からなる候補記事全てに対するスコア計算を行うがあります。
そこで今回ver.1として、少しふわっとしてますが
- 記事APIが行う計算部分は行列演算のみで済む線形モデル
- 線形モデルの各項に非線形な効果が入るように非同期なタスクを裏側で走らせておく
このようなスコア計算モデルを設計しました。
これにより、記事APIが行う処理は行列演算のみなので現実的な時間内にレスポンスすることが可能になり、かつ非線形な効果も入るのでそこそこ良いモデルになっています。
より詳細に(と言ってもマル秘を含みますが)解説するために、まず線形モデルに組み込まれるユーザーの特徴量が生成されるまでの流れを説明します:
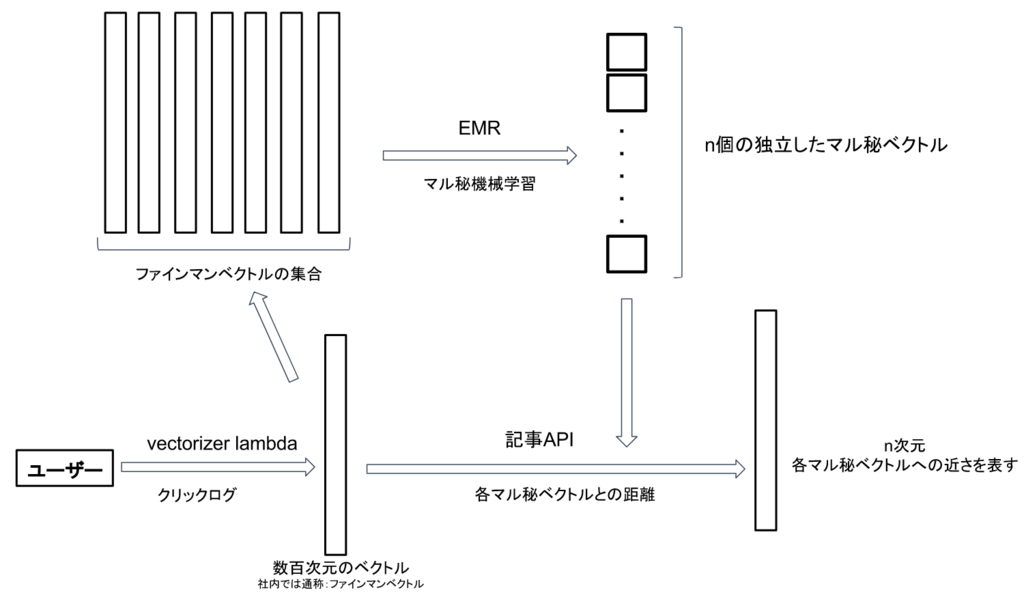
>1. ユーザーはクリックするたびに社内ではファインマンベクトルと
呼ばせている呼ばれているベクトルがリアルタイムに生成かつ更新される
2. 1.とは非同期に、ある時点でのファインマンベクトルを大量に用いて、Sparkで実装されたマル秘機械学習アルゴリズムでn個のマル秘ベクトルを生成する
3. 記事APIは、ユーザーがリクエストしたタイミングのそのユーザーのファインマンベクトルと、2.で生成されたn個のマル秘ベクトルとの距離(みたいなもの)を計算と言った感じです。ここで出来上がるユーザーの特徴量を wu∈Rn
としておきます。
次に線形モデルに入力される記事の特徴量についてです。ファインマンベクトルの生成方法とマル秘機械学習アルゴリズムのおかげで、記事に関しても n個のマル秘ベクトルとの”近さ”を複数の尺度(=:m
)で測る事が出来ます。
つまり、 複数のn次元ベクトル {wai}mi=1⊂Rn
を生成することができます。
これらを用いてスコア計算モデルst
を
st(u,a):=TimeDecay(t,a)×(∑i=1mαi×⟨wu,wai⟩), t:リクエスト時間
として設計します。このモデルは全てベクトルの内積と和の操作で完結するため、非常に高速に計算することが出来ます。
ここで TimeDecay(t,a)
は時間減衰関数(time decay function)と呼ばれるユーザーからのリクエスト時間とニュース記事の情報を引数とした関数で、「基本的には時間が経つほど値が小さくなる関数」となっています。
>また、α1,…,αn
はハイパーパラメータと呼ばれ、各独立したスコア⟨wu,wai⟩
を最終的なスコアにどの程度寄与させるかの重みです。
このハイパーパラメータを上手く調整することで全く気色の異なった記事リストをレスポンスしたりすることが出来ます。
もちろん各種教師あり学習アルゴリズムを用いて最適化することも出来ますが、問題設定上限られた目的関数しか設定できないため最善とは言えません。
そこで私達はこのハイパーパラメータのチューニング問題をSimulation Optimization問題として定式化して最適化するタスクを実行することにしました:
>§5. Simulation Optimizationによるハイパーパラメータ最適化
システムのハイパーパラメータを柔軟なKPIに関して最適化したい場合どうすれば良いのでしょうか。例えばユーザーの滞在時間に関して最適化したい場合、パラメータと滞在時間の関係が明示的に与えることが不可能なため勾配法などを使って最適化することができません。このように入力と出力の関係が不明なまま最適化を行う問題をBlackBox関数の最適化問題と呼びます。
BlackBox関数の最適化問題は
1. 出力が確率的に揺らがない場合
2. 出力が確率的に揺らぐ場合の2つに分類することができます。確率的に揺らがないとは、入力に関して出力が一意的に決まるという意味です。1. はDerivative Free Optimizationと呼ばれる分野で、2. はSimulation Optimizationと呼ばれる分野で今なお盛んに研究されています。
今回私達が設計したKPIは確率的なゆらぎを持っており、Simulation Optimizationに属する問題設定でした。
- 記事APIからのログの工夫
- 記事APIの実装とハイパーパラメータの分離
を行うことでSimulationOptimizationのとあるアルゴリズムとその結果をスムーズに反映することが可能となりました。
SimulationOptimizationについて詳細は後日データ分析ブログで別途解説しますが、気になる方は次のサーベイ論文を読むことをおすすめします:
[1706.08591] Simulation optimization: A review of algorithms and applications
>6. パーソナライズされた記事APIの処理
最後になりますが、ちょっとしたコード付きで記事APIの処理フローについてざっくり解説します。
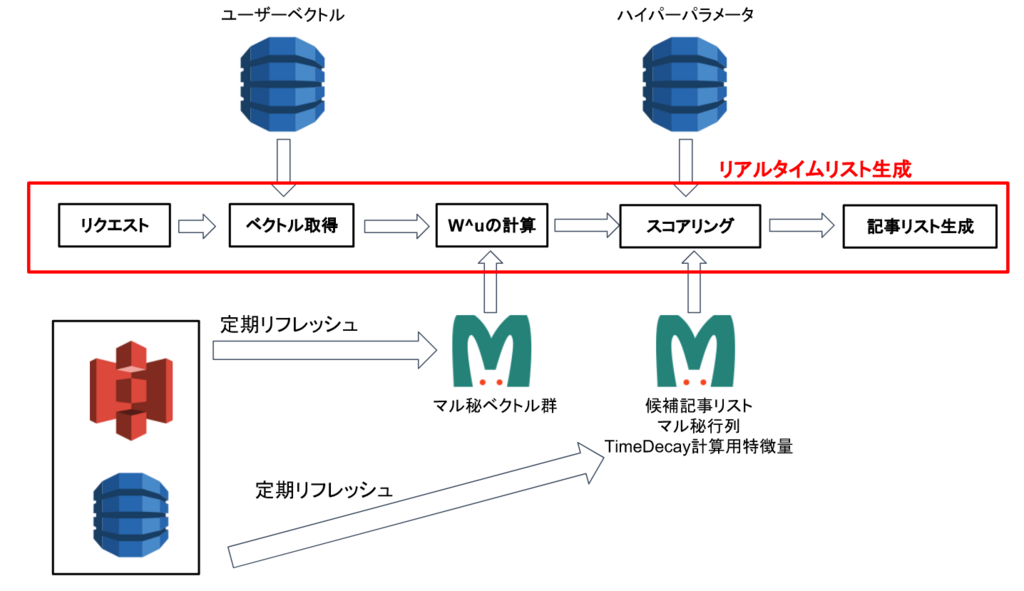
0. 時刻t
にリクエストを受ける
1. DynamoDBにユーザーベクトルを取りに行く
2. wu∈Rnを計算する
3. 候補記事全てに対して st(wu,a)を計算する (waiは事前計算しておく
)
4. 候補記事をスコアでソートし、上位数件をレスポンスするといった処理フローになっています。例えば3.の部分は次のようなコードになっています:
import "gonum.org/v1/gonum/mat" // aNum := 候補記事数 Score1 := mat.NewDense(aNum, 1, nil) Score2 := mat.NewDense(aNum, 1, nil) res := mat.NewDense(aNum, 1, nil) /* aFeature1 := article数 x n の行列. aFeature2 := articles数 x n の行列. */ // 内積処理 <w^a_i, w^u> に相当 Score1 = Score1.Mul(aFeature1, Wu) Score2 = Score2.Mul(aFeature2, Wu) // ハイパーパラメータによるスケーリング Score1.Scale(alpha1, Score1) Score2.Scale(alpha1, Score2) // 和を取る(= Σの部分) res.Add(res, Score1) res.Add(res, Score2)
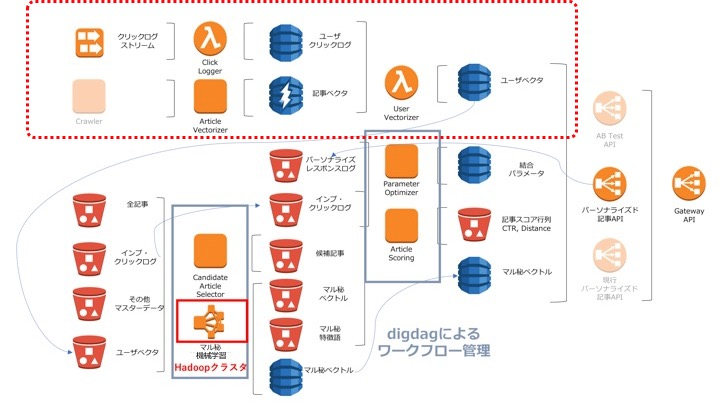
>課題と背景
弊社では以前からも様々なプロダクトで、行動履歴ログからベクトルを生成していました。が、ユーザの興味嗜好の変化をより早く反映、新規ユーザの趣味嗜好をより早く反映し、最適な情報を届けるために、旧来のバッチ型アーキテクチャから脱却し、リアルタイム(イベントドリブン)でのユーザベクトル生成を目指しました。
アーキテクチャ概要
ユーザベクトルの生成の流れを簡単にまとめると、下記の流れになります。
- 記事収集と同時に、記事の持つ様々な特徴量を駆使しdenseな記事ベクトルを生成
- ユーザが過去にクリックした記事(およびその際のcontext)のリストを生成
- 上記クリックした記事のベクトルにcontextによって重みを付け、その和を正規化しユーザベクトルを生成
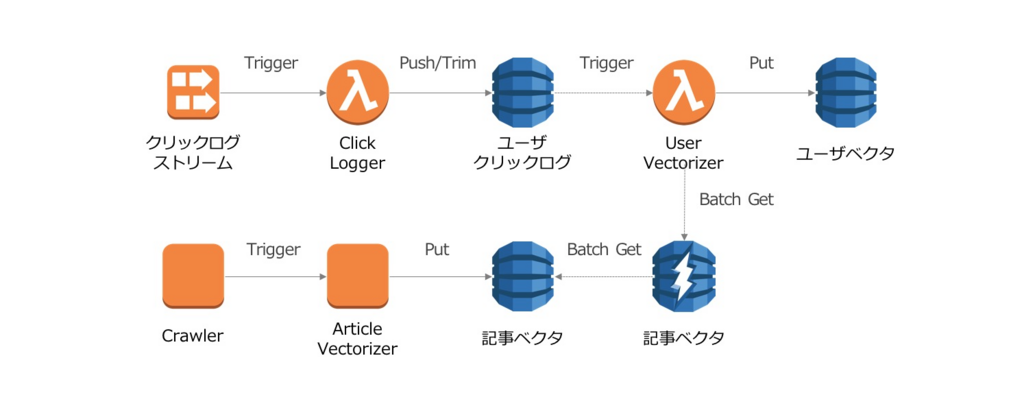
>それぞれ、図中のそれっぽい箇所に対応しています。
ベクトル自体の話については前回と同じく大人の事情により余り多くは語れないので、それ以外の部分で語っていきたいと思います。
ユーザの行動履歴(クリックした記事・context)の保持
冒頭でも触れましたが、いわゆるバッチ的に生ログから更新対象ユーザのログを検索し、時系列順にソートして取得するのは、なかなか時間もマシンパワー(すなわち💰)も必要でした。
リアルタイムにベクトル生成をするために、ユーザID一発でGetすることができて、そして揮発しないログストアが欲しく、今回は、DynamoDBのList型を利用することにしました。(下記は雑なイメージです)
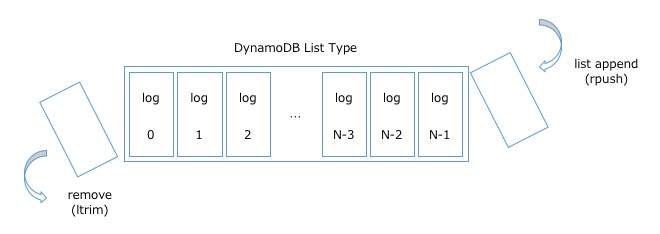
>DynamoDBには1項目あたり400KBという制限がありますが、クリックした記事と少しのcontextに限定すれば、そこそこの件数が詰められます。1logのサイズからListに詰められる件数を逆算し、list_appendで詰められるだけ詰め(push)、溢れそうになったらremoveで古いlogを追い出していくことで(trim)、ユーザID一発で至近N件のlogをGetできるようになりました。
これを、クリックログが入ってくるKinesis StreamsをTriggerとし、Lambda内でUserID毎にPush/Trimすることで、ほぼ遅延なくDynamoDBに反映することができました。
ユーザの行動履歴の更新に合わせ記事ベクトルを取得
ユーザの行動履歴が更新されるたびに、ユーザベクトルの更新が走ります。ユーザベクトルの更新のためには、最大N件の記事ベクトルを取得(BatchGet)する必要があります。
アーキテクチャの図にもありますが、DynamoDBに入っている記事ベクトルを素直に毎度Getしていると、レイテンシの懸念だけでなく、油田(すなわち💰)も必要になります。こういうケースの場合、当然前段にキャッシュサーバを挟むと思いますが、ただのGetOrSetならいざしらず、BatchGetOrSetを真面目にコード書くのは面倒です。
下記、弊社エンジニアmosa_siruの資料ですが(良い資料です)、直感的にはわかるもののいざ自分でコードを書き始めてみようとするとなかなか大変です。
関連記事 - More from my site -
 Swagger API(REST API)とDB定義チェック表
Swagger API(REST API)とDB定義チェック表 【工事中】Firebaseことはじめ on Mac
【工事中】Firebaseことはじめ on Mac Nginx cache無効化
Nginx cache無効化 Redisインストールから冗長化構成, Redis Sentinelによるフェイルオーバー CentOS6
Redisインストールから冗長化構成, Redis Sentinelによるフェイルオーバー CentOS6 MySQL xxx doesn’t have a default value
MySQL xxx doesn’t have a default value Mac VSCode phpcs PSR2コード規約
Mac VSCode phpcs PSR2コード規約 Ajax jQuery 基本フォーム処理
Ajax jQuery 基本フォーム処理 【工事中】Laravel クエリビルダ ->where()まとめ
【工事中】Laravel クエリビルダ ->where()まとめ RTX1210, 1200 GUIでの拠点間VPNが繋がらない時のチェック YAMAHA
RTX1210, 1200 GUIでの拠点間VPNが繋がらない時のチェック YAMAHA 線形代数 行列式(2次, 3次) サラスの公式
線形代数 行列式(2次, 3次) サラスの公式 Go Echo isconに向けたお勉強
Go Echo isconに向けたお勉強 最短経路 順列
最短経路 順列 Cookie, SessionStorage, LocalStorageについて
Cookie, SessionStorage, LocalStorageについて 標準誤差 SE Standard Error
標準誤差 SE Standard Error