
関連
- GCP CLI設定 CloudFunctions+BigQuery+CloudRun+ESPv2+独自ドメイン①
- GCP BigQueryの作成 CloudFunctions+BigQuery+CloudRun+ESPv2+独自ドメイン②
- GCP CloudFunction 関数の作成 CloudFunctions+BigQuery+CloudRun+ESPv2+独自ドメイン③
- GCP CloudRun + ESPv2によるAPI Gatewayリバースプロキシの作成④ CloudFunctions+BigQuery+CloudRun+ESPv2+独自ドメイン
データセット └ テーブル・ビュー
データセットはコンテナのようなもの
テーブルの確認
% bq ls -p
projectId friendlyName
------------------------------- -------------------------------
test-cloud-functions-20211208 test-cloud-functions-20211208
データセット作成
$ bq mk test_dataset_kanehiro Dataset 'test-cloud-functions-20211208:test_dataset_kanehiro' successfully created.
テーブルの作成
login_histories.json
[
{
"name": "user_id",
"type": "INTEGER",
"mode": "REQUIRED"
},
{
"name": "anonymous_token",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "login_type",
"type": "STRING",
"mode": "REQUIRED"
},
{
"name": "created_at",
"type": "TIMESTAMP",
"mode": "REQUIRED"
}
]
変数定義
PROJECT_ID=test-cloud-functions-20211208
DATASET=test_dataset_kanehiro
TABLE_NAME=${DATASET}.login_histories
テーブル作成
- created_atに日別でPartitioning
- user_idでclustering_fields指定
$ bq mk \
--project_id=${PROJECT_ID} \
--schema login_histories.json \
--time_partitioning_type=DAY \
--time_partitioning_field=created_at \
--clustering_fields=user_id \
--use_legacy_sql=false \
--table ${TABLE_NAME}
Table 'test-cloud-functions-20211208:test_dataset_kanehiro.login_histories' successfully created.
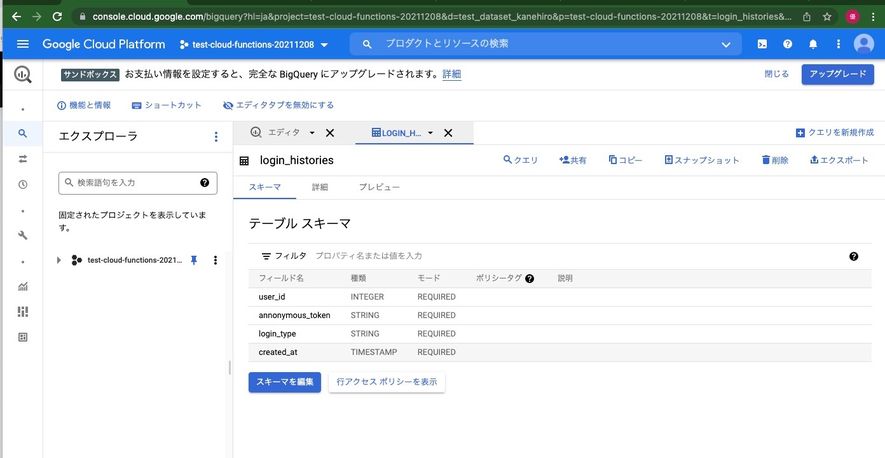
% bq show test_dataset_kanehiro.login_histories
Table test-cloud-functions-20211208:test_dataset_kanehiro.login_histories
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Labels
----------------- ---------------------------------------- ------------ ------------- ----------------- ------------------- ------------------ --------
08 Dec 17:07:11 |- user_id: integer (required) 0 0 06 Feb 17:07:10
|- annonymous_token: string (required)
|- login_type: string (required)
関連記事 - More from my site -
 PHPの継承 Interface 抽象クラスabstract 多重継承Trait
PHPの継承 Interface 抽象クラスabstract 多重継承Trait- Postfix キューの削除
 AWS Plesk Onyxログイン方法
AWS Plesk Onyxログイン方法![[Git] masterでの作業を別ブランチに移動させる](https://www.yuulinux.tokyo/contents/wp-content/plugins/wordpress-23-related-posts-plugin/static/thumbs/12.jpg) [Git] masterでの作業を別ブランチに移動させる
[Git] masterでの作業を別ブランチに移動させる ドメインのWhois情報公開すべきか代理公開か?
ドメインのWhois情報公開すべきか代理公開か? docker-compose Error Bind for 0.0.0.0:xxxxx failed: port is already allocated
docker-compose Error Bind for 0.0.0.0:xxxxx failed: port is already allocated![[Solved] SourceTree pre-commit hook exited with code 127](https://www.yuulinux.tokyo/contents/wp-content/plugins/wordpress-23-related-posts-plugin/static/thumbs/30.jpg) [Solved] SourceTree pre-commit hook exited with code 127
[Solved] SourceTree pre-commit hook exited with code 127 Wiresharkフィルタリング
Wiresharkフィルタリング- RFIDについて
 Laravel MiddlewareミドルウェアでIP制限機能をつくろう
Laravel MiddlewareミドルウェアでIP制限機能をつくろう- 自動車教習所
 ActiveDirectory スペックとDC数の推奨値、障害対応について。
ActiveDirectory スペックとDC数の推奨値、障害対応について。 Firebase Cloud Functions new Date() 日付がずれる Asia/Tokyoに設定
Firebase Cloud Functions new Date() 日付がずれる Asia/Tokyoに設定 Cisco HSRP
Cisco HSRP